
目录
一、引言

大家好呀!今天想和大家分享一下如何基于开源的 Stable Diffusion 大模型训练 Lora 来绘制超可爱的像素风动漫图。
二、Stable Diffusion 大模型
Stable Diffusion 是一款强大的深度学习模型,能够根据输入的提示和条件生成逼真的图像。它的出现极大地改变了图像生成的领域,为艺术家和创作者提供了新的工具和灵感。
推荐几个好用的模型网站:
可以了解自己喜欢的模型(合适的底模是训练属于自己的Lora的基础)
https://civitai.com/(需要科学上网)
https://huggingface.co/(模型资源多,不用科学上网,下载速度快)
stable-diffuson官模地址(一定要先上手会使用官模)
https://huggingface.co/CompVis/stable-diffusion-v1-4
三、Lora 训练的原理与部分操作流程
Lora(Low-Rank Adaptation)是一种轻量级的模型训练方法,可以在不改变原始大模型的基础上,针对特定的任务或风格进行微调。在绘制像素风动漫图方面,Lora 能够快速捕捉到像素风格的特征,提高生成图像的质量和风格一致性。
1.数据准备
收集大量与您想要训练的主题或风格相关的图像数据。建议使用至少几百张图像素材来获得较好的效果,但具体数量取决于多个因素。我这边训练的是像素风Lora,使用到了一百张像素动漫角色图。 对数据进行清洗、筛选和预处理,例如调整图像大小、裁剪、归一化等。检查图片类型符合像素风格,推荐使用统一尺寸的图进行训练,可以提高训练效率。 打标操作,对收集到的图片数据集统一进行打标,可以通过stable-diffusion插件选择“数据集标签编辑器”进行打标,打标时需要进行关键词排查,删去不合理的关键词,同时统一添加pixel art(像素艺术)标签。
2.环境搭建和基础模型选择
安装所需的深度学习框架,如 PyTorch。因为只是素材不多的Lora训练,我这边选择Colab配合谷歌硬盘Drive进行Lora训练(Colab新用户可白嫖一段时间的Gpu使用,提高训练效率。专业模型训练还是推荐使用autodl快速部署训练) 打包好的可视化训练文档链接:
https://colab.research.google.com/github/WSH032/lora-scripts/blob/main/Colab_Lora_train.ipynb
具体流程不多说,参考下面教程
https://www.bilibili.com/video/BV1MM4y1U7Ba/?spm_id_from=333.976.0.0
底模我选择novelailatest-pruned----基于 NovelAI 相关技术的一个经过剪枝处理的模型。
训练参数推荐学习B站秋葉aaaki,青龙圣者两位大佬视频学习配置,需要根据训练目标和效果调整。不同的损失函数参数可能相互影响,因此需要尝试同时调整多个参数的组合,以找到最优的平衡。由于像素风训练侧重风格的一致性或特定风格的生成,我们可以稍微提高风格损失的权重。
由于训练过程长,需要大量时间,建议在训练过程中采样以便于实时查看训练效果,方便后续选择最满意的训练模型。
3.使用训练好的Lora搭配底模出图
如果电脑配置可以,可以选择本地部署stable-diffusion的webui进行画图,如果想要更高效还是租个服务器好了。
用lora配套的大模型出图效果更好--比如我训练使用的是novelailatest-pruned底模,这边也使用novelailatest-pruned搭配Lora来画图。
一定要使用触发词--比如我的像素风Lora需要在Prompt中添加pixel art(像素艺术)来触发。
先学习如何使用和调参
(1)Sampler——采样方式,在Stable Diffusion WebUI中的Sampling method中进行选择
(2)Model——作者使用的大模型,在Stable Diffusion WebUI中的Stable Diffusion checkpoint中进行选择
(3)CFG scale——提示词相关性,在Stable Diffusion WebUI中的CFG scale进行调整
(4)Steps——采样迭代步数,在Stable Diffusion WebUI中的Sampling steps中进行调整
(5)Seed——随机种子,在Stable Diffusion WebUI中的Seed中进行调整
提示
切记:尽量不要混用lora,会互相污染,效果更差
四、成果展示
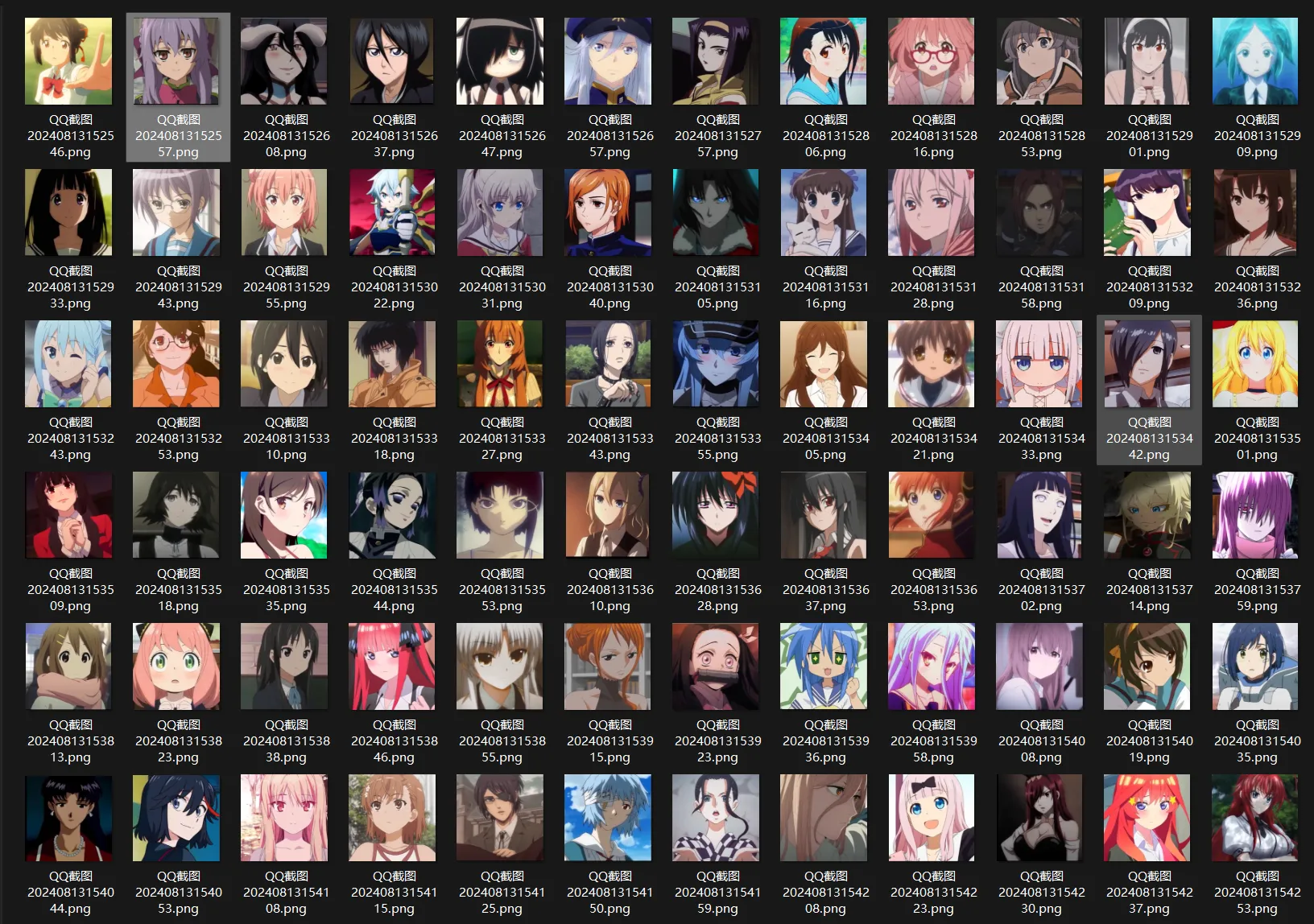
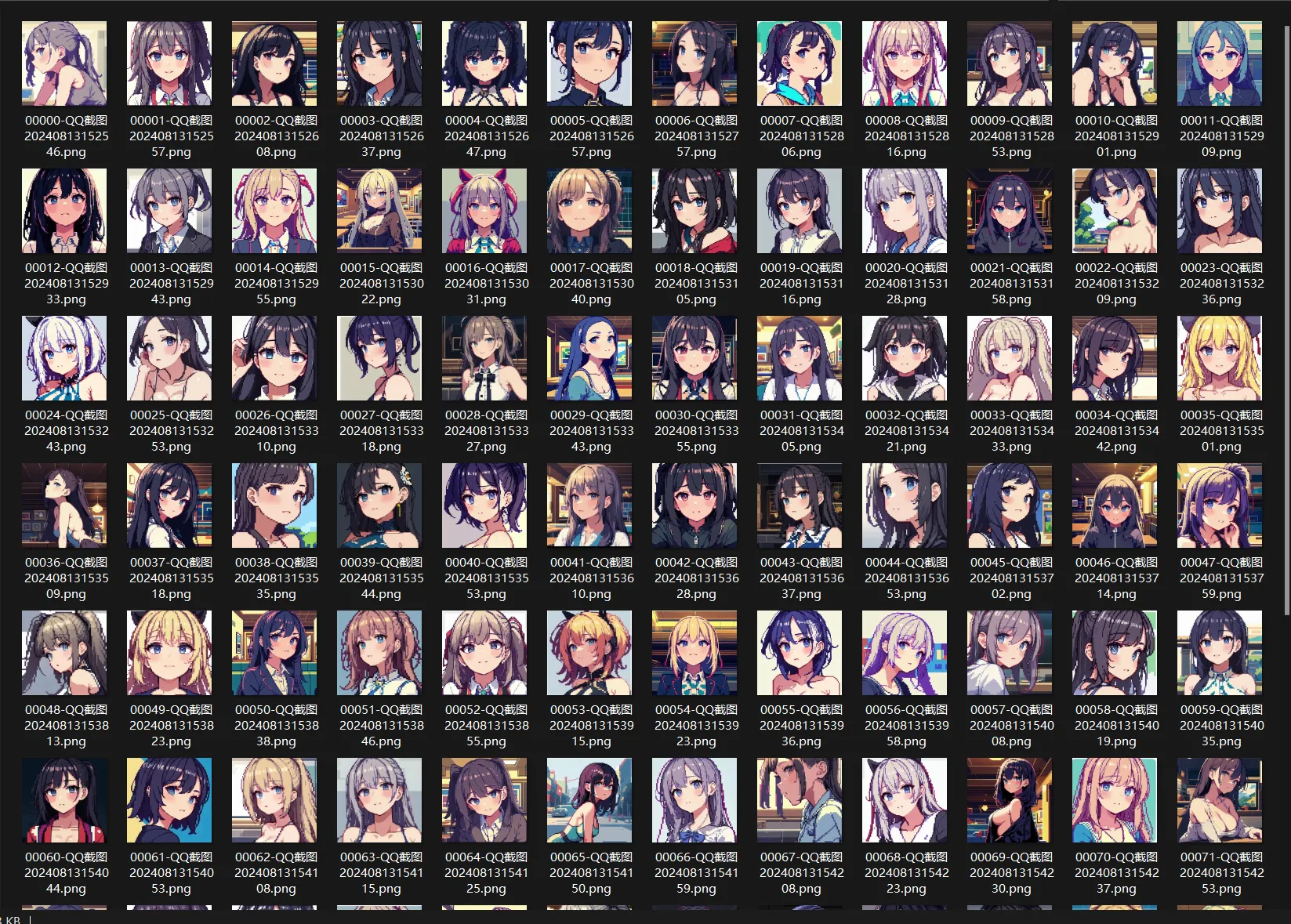
选取了2024年动漫女角色排名前一百并进行像素化批处理(由于是批处理操作没有对每张图片单独打角色标签,没有针对具体角色进行具体Lora训练,因此生成的像素图更多受到底模影响,着重关注图片形态特征,不保留角色样貌特征)
素材:
结果:
本文作者:han
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!